

Apache Cassandra e Apache Hadoop são membros da mesma família Apache Software Foundation. Poderíamos ter contrastado essas duas estruturas, mas essa comparação não seria justa porque Apache Hadoop é o ecossistema que abrange vários componentes. Como Cassandra é responsável por armazenamento de big dataescolhemos o equivalente do ecossistema do Hadoop, que é Sistema de arquivos distribuído Hadoop (HDFS). Cassandra e HDFs desfrutam de ampla adoção entre as empresas. De acordo com o Relatório da comunidade Cassandra41% das organizações pesquisadas usam Cassandra como seu banco de dados principal, com 50% de seus dados sendo tratados por ele. O mercado Hadoop (juntamente com HDFs como componente da estrutura) também indica altas taxas de adoção e é projetado atingir US $ 1.560 bilhões até 2033.
Aqui, tentaremos descobrir se Cassandra e HDFs são como gêmeos que são idênticos na aparência e apenas têm nomes diferentes, ou são um irmão e uma irmã que podem parecer semelhantes, mas ainda são muito diferentes.

Mestre/escravo vs. Arquitetura sem Master
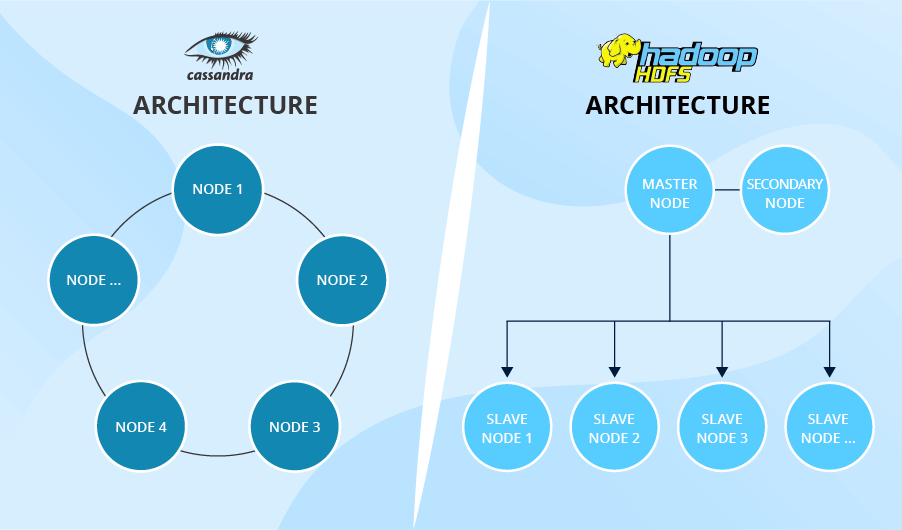
Antes de nos debatermos sobre as características que distinguem HDFs e Cassandra, devemos entender as peculiaridades de suas arquiteturas, pois elas são a razão de muitas diferenças de funcionalidade. Se você olhar para a foto abaixo, verá dois conceitos contrastantes. A arquitetura do HDFS é hierárquica. Ele contém um nó principal, bem como numerosos nós de escravos. Pelo contrário, a arquitetura de Cassandra consiste em vários nós ponto a ponto e se assemelha a um anel.
5 principais diferenças funcionais
1. Lidando com conjuntos de dados maciços
Tanto o HDFS quanto o Cassandra foram projetados para armazenar e processar conjuntos de dados maciços. No entanto, você precisaria fazer uma escolha entre esses dois, dependendo dos conjuntos de dados com os quais você precisa lidar. O HDFS é uma escolha perfeita para escrever arquivos grandes. O HDFS foi projetado para pegar um arquivo grande, dividi -lo em vários arquivos menores e distribuí -los pelos nós. De fato, se você precisar ler alguns arquivos do HDFS, a operação é reversa: o HDFS deve coletar vários arquivos de diferentes nós e fornecer algum resultado que corresponda à sua consulta. Por outro lado, Cassandra é a escolha perfeita para escrever e ler vários pequenos discos. Sua arquitetura sem mestre permite gravar e lê rápido em qualquer nó. Alto Performance de Cassandra Faz de solutar arquitetos optar pelo banco de dados se for necessário funcionar com dados de séries temporais, o que geralmente é a base da Internet das Coisas.
Enquanto, em teoria, HDFs e Cassandra parecem mutuamente exclusivos, na vida real eles podem coexistir. Se continuarmos com o IoT big datapodemos criar um cenário em que o HDFS é usado para um lago de dados. Nesse caso, novas leituras serão adicionadas aos arquivos Hadoop (digamos, haverá um arquivo separado por cada sensor). Ao mesmo tempo, um data warehouse pode ser construído no Cassandra.
2. Resistindo a falhas
HDFs e Cassandra são considerados confiáveis e resistentes à falha. Para garantir isso, ambos aplicam replicação. Simplificando, quando você precisa armazenar um conjunto de dados, HDFs e Cassandra o distribuem para algum nó e criar as cópias do conjunto de dados para armazenar em vários outros nós. Portanto, o princípio da resistência a falhas é simples: se algum nó falhar, os conjuntos de dados que ele continham não são irremediavelmente perdidos – suas cópias ainda estão disponíveis em outros nós. Por exemplo, por padrão, o HDFS criará três cópias, embora você esteja livre para definir qualquer outro número de réplicas. Só não se esqueça que mais cópias significam mais espaço de armazenamento e mais tempo para executar a operação. Cassandra também permite escolher os parâmetros de replicação necessários.
No entanto, com sua arquitetura sem mestrado, Cassandra é mais confiável. Se o nó principal e o nó secundário do HDFS falhar, todos os conjuntos de dados serão perdidos sem a possibilidade de recuperação. Obviamente, o caso não é frequente, mas isso ainda pode acontecer.
3. Garantir a consistência dos dados
O nível de consistência dos dados determina quantos nós devem confirmar que armazenaram uma réplica para que toda a operação de gravação seja considerada um sucesso. Em caso de operações de leitura, o nível de consistência dos dados determina quantos nós devem responder antes que os dados sejam retornados a um usuário.
Em termos de consistência dos dados, HDFs e Cassandra se comportam de maneira bastante diferente. Digamos que você peça aos HDFs que escrevam um arquivo e criem duas réplicas. Nesse caso, o sistema se referirá ao nó 5 primeiro, depois o nó 5 pedirá ao Nó 12 para armazenar uma réplica e, finalmente, o nó 12 pedirá ao Node 20 que faça o mesmo. Somente depois disso, a operação de gravação é reconhecida.
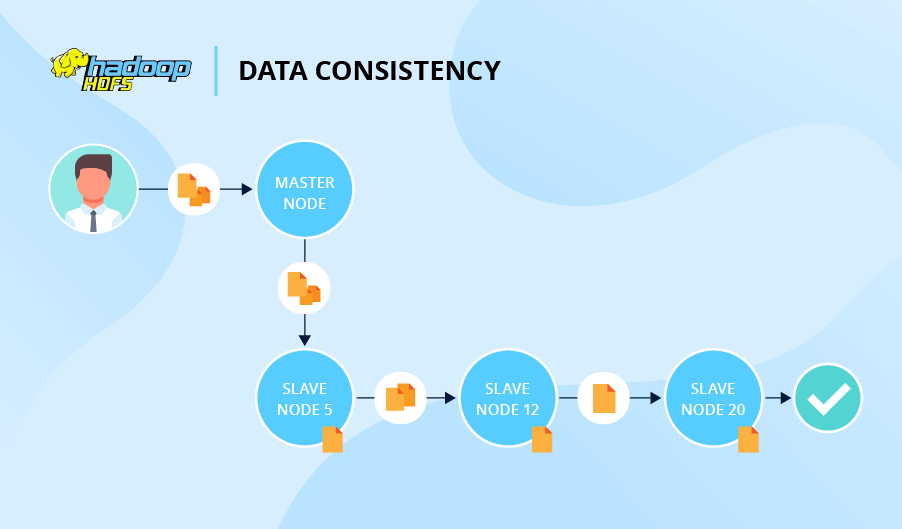
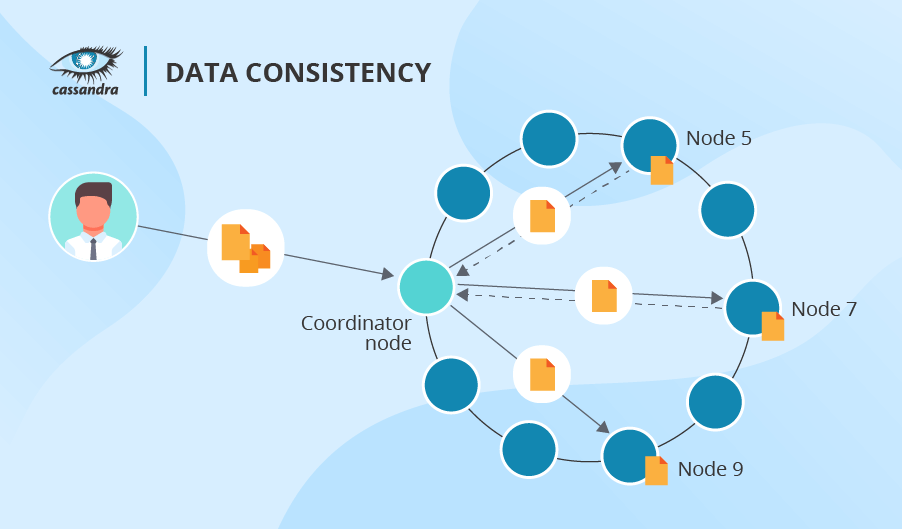
Cassandra não usa a abordagem seqüencial do HDFS, então não há fila. Além disso, Cassandra permite que você declare o número de nós que deseja confirmar o sucesso da operação (pode variar qualquer nó para todos os nós respondendo). Mais uma vantagem do Cassandra é que ele permite diferentes níveis de consistência de dados para cada operação de gravação e leitura. A propósito, se uma operação de leitura revelar inconsistência entre as réplicas, o Cassandra inicia um reparo de leitura para atualizar os dados inconsistentes.
4. Indexação
Como os dois sistemas funcionam com enormes volumes de dados, a verificação de apenas uma certa parte do big data em vez de uma varredura completa aumentaria a velocidade do sistema. A indexação é exatamente o recurso que permite fazer isso.
Tanto o Cassandra quanto o HDFS suportam a indexação, mas de maneiras diferentes. Embora a Cassandra tenha muitas técnicas especiais para recuperar dados mais rapidamente e até mesmo a criação de vários índices, os recursos do HDFS vão apenas para um determinado nível – para os arquivos em que o conjunto de dados inicial foi dividido. No entanto, a indexação em nível de registro pode ser alcançada com o Apache Hive.
5. Entregando análises
Ambos projetados para armazenamento de big data, Cassandra e HDFs ainda têm a ver com a análise. Não por si mesmos, mas em combinação com estruturas especializadas de processamento de big data, como o Hadoop MapReduce ou Apache Spark.
O ecossistema do Apache Hadoop já inclui o MapReduce e o Apache Hive (um mecanismo de consulta) junto com o HDFS. Como descrito acima, o Apache Hive ajuda a superar a falta de indexação no nível de registro, o que permite acelerar uma análise intensiva em que o acesso aos registros é necessário. No entanto, se você precisar Funcionalidade do Apache Sparkvocê pode optar por essa estrutura, pois também é compatível com o HDFS.
O Cassandra também é executado sem problemas, juntamente com o Hadoop MapReduce ou o Apache Spark, que podem ser executados em cima desse armazenamento de dados.
HDFs e Cassandra no quadro do teorema do CAP
De acordo com o teorema do CAP, um armazenamento de dados distribuído pode suportar apenas dois dos três recursos a seguir:
- Consistência: Uma garantia de que os dados estão sempre atualizados e sincronizados, o que significa que, a qualquer momento, qualquer usuário receberá a mesma resposta à sua consulta de leitura, independentemente de qual nó o retorne.
- Disponibilidade: uma garantia de que um usuário sempre receberá uma resposta do sistema dentro de um tempo razoável.
- Tolerância de partição: uma garantia de que o sistema continuará a operação, mesmo que alguns de seus componentes estejam inativos.
Se olharmos para HDFs e Cassandra da perspectiva do teorema do CAP, o primeiro representará CP e o último – propriedades AP ou CP. A presença de consistência na lista de Cassandra pode ser bastante intrigante. Mas, se necessário, seus especialistas em Cassandra podem ajustar o fator de replicação e os níveis de consistência dos dados para gravações e leituras. Como resultado, Cassandra perderá a garantia de disponibilidade, mas ganhará muito em consistência. Ao mesmo tempo, não há possibilidade de alterar a orientação do teorema do CAP para HDFs.
Em poucas palavras
A partir da descrição acima, pode parecer que Cassandra supera amplamente os HDFs. Ainda assim, se considerarmos os bancos de dados no contexto de seus respectivos casos de uso, veremos que ambos tenham seus usos ideais, dependendo do tipo de dados e de seu objetivo. Abaixo, você pode ver a comparação de diferentes parâmetros de banco de dados e como eles fazem um ajuste perfeito para cenários específicos.
| Parâmetro | Cassandra | HDFS |
|---|---|---|
| Escreva latência |
Muito baixo. As gravações são distribuídas entre nós e reconhecidas rapidamente, especialmente em níveis mais baixos de consistência. |
Moderado a alto. Leva tempo para coordenar as gravações através do namenode e replicação. |
| Leia a latência |
Muito baixo. Cassandra suporta leituras de acesso aleatório de qualquer nó no cluster. |
Moderado a alto. O HDFS precisa remontar dados de vários nós para leitura. |
| Escalabilidade |
Altamente escalável. A arquitetura sem -master permite adicionar e remover nós com interrupção mínima. A tecnologia garante replicação e consistência altamente configuráveis. |
Moderadamente escalável. O HDFS conta com um único namenode, que limita a escalabilidade para aglomerados grandes. A replicação por arquivo e diretório é menos flexível do que as configurações por operação da Cassandra. |
| Melhores casos de uso de uma perspectiva técnica |
|
|
| Melhores casos de uso de uma perspectiva de negócios |
|
|
Você poderia fazer uma pergunta razoável: e se eu quiser ter o melhor dos dois mundos e combinar as capacidades em tempo real de Cassandra com o poder de processamento de lote dos HDFs? É possível! Com profissional Hadoop e Cassandra Consultoria, você pode escolher a pilha de tecnologia ideal para o seu caso ou aprender a se beneficiar de uma abordagem híbrida.
Leave a Reply