
A Nvidia disse que alcançou uma velocidade de inferência recorde de modelo de idioma (LLM), anunciando que um NVIDIA DGX B200 Nó com oito GPUs Nvidia Blackwell alcançou mais de 1.000 Tokens por segundo (TPS) por usuário no modelo de 400 bilhões de parâmetros LLAMA 4 Maverick.
Nvidia disse que o modelo é o maior e mais poderoso da coleção Llama 4 e que a velocidade foi medida independentemente pelo Análise artificial de serviço de benchmarking de IA.
A NVIDIA acrescentou que Blackwell atinge 72.000 TPS/servidor na sua maior configuração de taxa de transferência.
A empresa disse que fez otimizações de software usando Tensorrt-llm e treinaram um modelo de rascunho especulativo usando Técnicas de Eagle-3. Combinando essas abordagens, a Nvidia alcançou uma aceleração 4X em relação à melhor linha de base anterior de Blackwell, disse a NVIDIA.
“As otimizações descritas abaixo aumentam significativamente o desempenho, preservando a precisão da resposta”, disse Nvidia em um blog publicado ontem. “Aproveitamos os tipos de dados FP8 para gemms, mistura de especialistas (MOE) e operações de atenção para reduzir o tamanho do modelo e usar a alta taxa de transferência de FP8 possível com Blackwell Tensor Core Technology. Precisão ao usar o formato de dados FP8 corresponde ao de Análise artificial BF16 em muitas métricas… ”” A maioria dos contextos de aplicativos de IA generativos requer um equilíbrio entre taxa de transferência e latência, garantindo que muitos clientes possam desfrutar simultaneamente de uma experiência “boa o suficiente”. No entanto, para aplicações críticas que devem tomar decisões importantes em velocidade, minimizar a latência para uma única cliente que se torna o Minimount. Como o MATERATIVO MATERIZATIVO (MINDATIMIZIDADE O BALANDO DE BALANDO A MELHORIA O MINDATIVO PARA MASTURTO PARA MATER. publicar).
Abaixo está uma visão geral das otimizações e fusões do kernel (indicadas em quadrados de corte vermelho) Nvidia aplicada durante a inferência. A NVIDIA implementou vários núcleos GEMM de baixa latência e aplicou várias fusões do kernel (como FC13 + Swiglu, FC_QKV + ATTN_SCALING e ALLREDUCE + RMSNORM) para garantir que o Blackwell se destaque no cenário mínimo de latência.
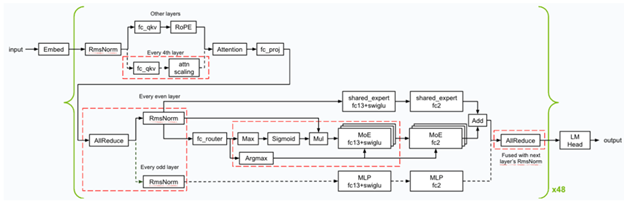
Visão geral das otimizações e fusões do kernel usadas para llama 4 Maverick
A NVIDIA otimizou os núcleos CUDA para operações de GEMMS, MOE e atenção para obter o melhor desempenho nas GPUs Blackwell.
- Utilizado particionamento espacial (também conhecido como especialização em Warp) e projetou os grãos GEMM para carregar dados da memória de maneira eficiente para maximizar a utilização da enorme largura de banda de memória que o sistema de banda NVIDIA DGX oferece – 64TB/S HBM3E BandWidth no total.
- Embaralhou o peso gemm em um Swizzed formato para permitir melhor layout ao carregar o resultado da computação de Memória tensorada Após os cálculos de multiplicação da matriz, usando os núcleos tensores de quinta geração de Blackwell.
- Otimizou o desempenho dos kernels de atenção dividindo os cálculos ao longo da dimensão do comprimento da sequência dos tensores K e V, permitindo que os cálculos sejam executados em paralelo em vários blocos de encadeamento CUDA. Além disso, a NVIDIA utilizou Memória compartilhada distribuída Para reduzir eficientemente os resultos nos blocos de threads no mesmo cluster de blocos de threads sem a necessidade de acessar a memória global.
O restante do blog pode ser encontrado aqui.
Leave a Reply